The Art of States and Transitions-I
Table of contents

This article assumes the reader has some familiarity with the concept of state-machines and related aspects like Finite State Machines (FSM), Automata Theory, and Transition Systems. Although this article portrays a concise picture of properly utilising a state machine, suffice to say that going through the aforementioned topics at one’s own pace would add valuable insight into this mode of application development.
This article focuses mainly on software development, but the concept can be incorporated to hardware development as well (albeit with specific domain knowledge and applicability).

Oftentimes it is observed that a particular flow of an application, or an entire application, can be modeled as a state machine and developed accordingly. And it is true that the state-machine model of development is just one of the various ways software can be developed, not excluding software-engineering principles.
State machines are a perfect fit for application development where tasks can be modeled as a sequence of activities resulting from inputs from the surrounding environment.
What are the benefits and/or drawbacks of state machines?
Benefits
1. Allows to abstract out business logic through well-defined states and transitions
2. If properly implemented, allows one to define a deterministic application by making impossible states impossible to occur. (However, this may not be possible if there is no way to express impossibility via type system, refer <a href="https://www.idris-lang.org/" target="_blank" style="color:#0057FF; text-decoration:none;">Idris</a> or <a href="https://wiki.portal.chalmers.se/agda/pmwiki.php" target="_blank" style="color:#0057FF; text-decoration:none;">Agda</a> for dependent type systems)
3. Allows for a more maintainable codebase through state isolation and testing
4. Allows for sub-states (i.e. states inside a state) that granularly represents business logic
Drawbacks
1. State explosion — Feature additions have to incorporate all possible states and transitions (including error states) for it to work. Soon one ends up with an explosive number of states as features increase, thereby decreasing the maintenance and interpretation capabilities
2. Parallelism — State machines are not so good at parallelism. If such need arises, it is better to develop applications through alternate models or to look at Queued State Machine (QSM) which is, out of many, well suited for event-driven producer-consumer architectures
3. Implementations for huge systems is difficult without proper knowledge and design of the entire system
One often overlooked and critical fact (frequently observed among developers during application development) is that the state-machine system is orthogonal to the application/business logic layer owing to the nature of inputs generated from the input/interaction layer. Orthogonality is a property that guarantees that modifying the technical effect produced by one component in the system will not have any side effects in other components of the system.
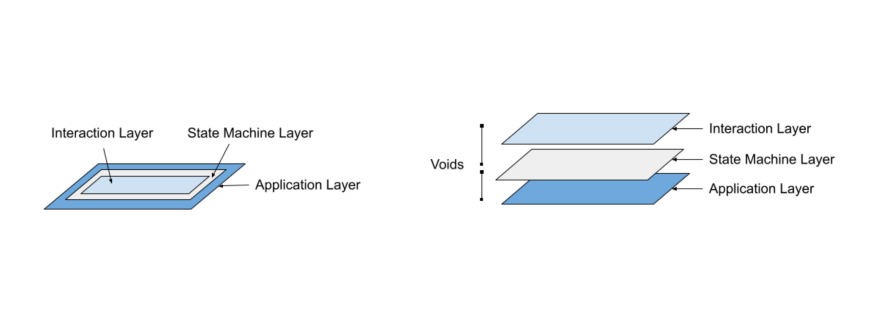
A zero-distance input/interaction layer (above left) essentially means the application is a thick client and doesn’t have any voids, i.e. having both the logic and interface coupled together in a single executable. A non-zero distance input/interaction layer (above right) implies a thin client, having at least one void, quite analogous to a client-server architecture, where the client behaves as an input/interaction layer for the server which is behaving as the business/application layer.
Typically, to drive the state of the entire application, the state-machine layer lies close to the application/business layer, although each layer can have its own association with another state-machine layer close to it.
Why is orthogonality important? This is the subject for the remainder of this article.
Time has a strong correlation with any state-machine implementation. Typically, time is represented in the x-axis with the right arrow denoting increasing time and subsequently the state-machine approaching its final state. There’s no left arrow for obvious reasons. Any self-loop or loop indicates that the machine has moved forward with time but has remained in the same state, or has come back to the state from which transition(s) originated, respectively.
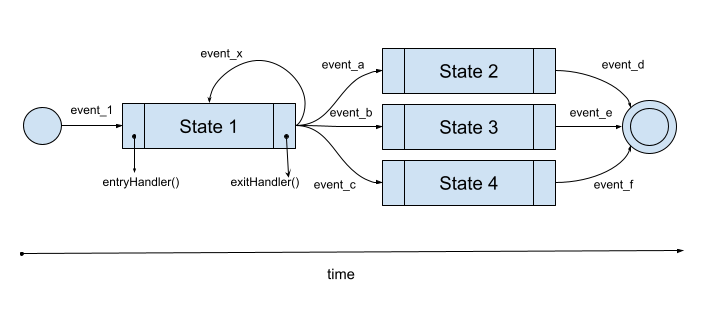
And that’s where the relation of state-machine to time ends because what follows is a series of confusions arising from the placement of logic in a state-machine:
1. Should the logic be written in the state?
A. Should the state have entry actions? If so, then who should be executing them: the transition to the current state, or this state itself?
B. Should the state have exit actions?
2. Should the logic be written in the transition?
A. Should the transition logic fire the next state’s entry condition (if entry condition exists) or is it up to the state to handle that?
3. Who handles the transitions: the machine or the current state?
All these are clarified when we essentially factor in orthogonality and time while implementing a state-machine.
Let’s take it step-by-step:
1. Transitions are named allowable events of the current state to take the state machine to the next state
2. Transitions may or may not be informed to the input/interaction layer; in case there’s only one transition and there’s no suitable name for it, a catch-all name, e.g. next(input), should be provided to move the machine forward
3. States are discrete points in time, acting as resting places; as such, entry and exit handlers should be treated as side-effects
4. A state by itself should not trigger any event; it can at most invoke a function (typically happens automatically or after a time period) after the machine enters this state
5. The state instructs the machine to transition it to the next state
Head on to the second part of this series (link <a href="https://www.getdefault.in/post/the-art-of-states-and-transitions-ii" style="color:#0057FF; text-decoration:none;">here</a>) to see how one can take a pragmatic approach to develop a state machine.
This article assumes the reader has some familiarity with the concept of state-machines and related aspects like Finite State Machines (FSM), Automata Theory, and Transition Systems. Although this article portrays a concise picture of properly utilising a state machine, suffice to say that going through the aforementioned topics at one’s own pace would add valuable insight into this mode of application development.
This article focuses mainly on software development, but the concept can be incorporated to hardware development as well (albeit with specific domain knowledge and applicability).
Oftentimes it is observed that a particular flow of an application, or an entire application, can be modeled as a state machine and developed accordingly. And it is true that the state-machine model of development is just one of the various ways software can be developed, not excluding software-engineering principles.
State machines are a perfect fit for application development where tasks can be modeled as a sequence of activities resulting from inputs from the surrounding environment.
What are the benefits and/or drawbacks of state machines?
Benefits
1. Allows to abstract out business logic through well-defined states and transitions
2. If properly implemented, allows one to define a deterministic application by making impossible states impossible to occur. (However, this may not be possible if there is no way to express impossibility via type system, refer <a href="https://www.idris-lang.org/" target="_blank" style="color:#0057FF; text-decoration:none;">Idris</a> or <a href="https://wiki.portal.chalmers.se/agda/pmwiki.php" target="_blank" style="color:#0057FF; text-decoration:none;">Agda</a> for dependent type systems)
3. Allows for a more maintainable codebase through state isolation and testing
4. Allows for sub-states (i.e. states inside a state) that granularly represents business logic
Drawbacks
1. State explosion — Feature additions have to incorporate all possible states and transitions (including error states) for it to work. Soon one ends up with an explosive number of states as features increase, thereby decreasing the maintenance and interpretation capabilities
2. Parallelism — State machines are not so good at parallelism. If such need arises, it is better to develop applications through alternate models or to look at Queued State Machine (QSM) which is, out of many, well suited for event-driven producer-consumer architectures
3. Implementations for huge systems is difficult without proper knowledge and design of the entire system
One often overlooked and critical fact (frequently observed among developers during application development) is that the state-machine system is orthogonal to the application/business logic layer owing to the nature of inputs generated from the input/interaction layer. Orthogonality is a property that guarantees that modifying the technical effect produced by one component in the system will not have any side effects in other components of the system.
A zero-distance input/interaction layer (above left) essentially means the application is a thick client and doesn’t have any voids, i.e. having both the logic and interface coupled together in a single executable. A non-zero distance input/interaction layer (above right) implies a thin client, having at least one void, quite analogous to a client-server architecture, where the client behaves as an input/interaction layer for the server which is behaving as the business/application layer.
Typically, to drive the state of the entire application, the state-machine layer lies close to the application/business layer, although each layer can have its own association with another state-machine layer close to it.
Why is orthogonality important? This is the subject for the remainder of this article.
Time has a strong correlation with any state-machine implementation. Typically, time is represented in the x-axis with the right arrow denoting increasing time and subsequently the state-machine approaching its final state. There’s no left arrow for obvious reasons. Any self-loop or loop indicates that the machine has moved forward with time but has remained in the same state, or has come back to the state from which transition(s) originated, respectively.
And that’s where the relation of state-machine to time ends because what follows is a series of confusions arising from the placement of logic in a state-machine:
1. Should the logic be written in the state?
A. Should the state have entry actions? If so, then who should be executing them: the transition to the current state, or this state itself?
B. Should the state have exit actions?
2. Should the logic be written in the transition?
A. Should the transition logic fire the next state’s entry condition (if entry condition exists) or is it up to the state to handle that?
3. Who handles the transitions: the machine or the current state?
All these are clarified when we essentially factor in orthogonality and time while implementing a state-machine.
Let’s take it step-by-step:
1. Transitions are named allowable events of the current state to take the state machine to the next state
2. Transitions may or may not be informed to the input/interaction layer; in case there’s only one transition and there’s no suitable name for it, a catch-all name, e.g. next(input), should be provided to move the machine forward
3. States are discrete points in time, acting as resting places; as such, entry and exit handlers should be treated as side-effects
4. A state by itself should not trigger any event; it can at most invoke a function (typically happens automatically or after a time period) after the machine enters this state
5. The state instructs the machine to transition it to the next state
Head on to the second part of this series (link <a href="https://www.getdefault.in/post/the-art-of-states-and-transitions-ii" style="color:#0057FF; text-decoration:none;">here</a>) to see how one can take a pragmatic approach to develop a state machine.
Give your product vision the talent it deserves
building your dream engineering team.



.webp)

